Solution
Our Data Science Approach
To tell our customers an optimal allocation of a budget between their various campaigns, we have a two step approach:
- Generating an Allocation of spending across campaigns.
- Testing Whether this allocation is optimal.
To help explain our data science pipeline, let’s start with the latter, testing whether an allocation is optimal.
Testing Whether an Allocation is Optimal
If we have 3 campaigns and a total budget of $1, we can allocate advertisement funding in many different ways: [1, 0, 0], [0.5, 0.2, 0.3], and so on. Similar to work done at Grid Dynamics, we evaluate an allocation of budgets by simulating the number of conversions against the dataset. This is done using the following steps:
- A row represents a single interaction a user had (i.e. saw advertisement). We order the rows by time.
- If a campaign has the budget to serve an ad to the individual, the row “passes” and the customer continues in their customer journey. We decrement the budget of the campaign by the cost to serve that ad.
- If, however, there isn’t budget, we must decide how likely that user is to convert. The option Grid Dynamics follows is to assume that they simply do not convert. Instead, we predict whether that user will convert given the journey they have had so far.
- To predict how likely they are to convert, we train simply train a model to predict conversion! The key assumption here is that a user who gets “cut off” at a particular stage in the funnel is similar to a user who converted/didn’t convert going through their entire funnel.
- Finally, we tally up the total number of conversions. The lowest total budget that has a total number of conversions equal to the number of conversions currently in the dataset is returned as the optimal allocation.
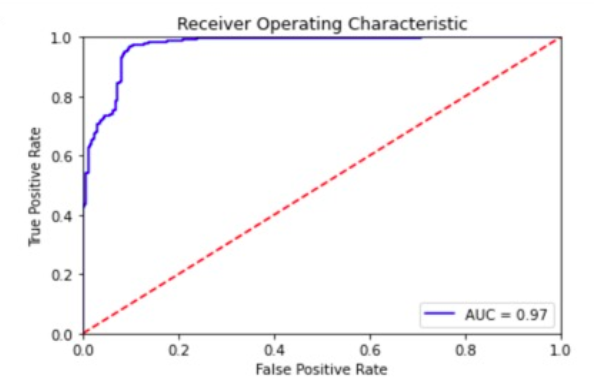
One of the key benefits of this approach is that it is dataset size agnostic. To simulate increasing conversions, we duplicate the dataset and simply pose the question as the necessary minimum budget needed to achieve as many conversions as exists in the dataset currently.
Generating a Proposed Allocation
To generate allocations across different scales of data, we simply tests every permutation of campaign budget allocation with a granularity of 10% variation between permutation. However, in the case when our dataset is not multiplied (i.e. the actual dataset submitted without duplicates), a special case emerges for generating an efficient allocation that enables us to use a neural network to create attribution weights.
The idea of using a neural network to predict customer conversion is a well studied problem in machine learning. Recent attempts have been made to use Long-Short Term Memory (LSTM) networks to model conversion by framing the prediction problem sequentially, treating each aspect of a customer journey as a timestep that is fed into a neural network (Shao and Li 2011). Some variants of these include attention mechanisms to supplement LSTM architectures.
More recently, these efforts in attention mechanisms, first originating in the field of natural language processing, have led to a broader interpretation of the attention weights in customer journey and conversion prediction as representing the importance of each journey step in the path to conversion (Arava 2018).
We train a neural network similar to prior work by Li, et al. but we modify the loss function used to account for the cost of serving ads and revenue. In a simulation of over 200 allocations, our neural network’s allocation recommendation outperforms all randomly selected allocations we tested.
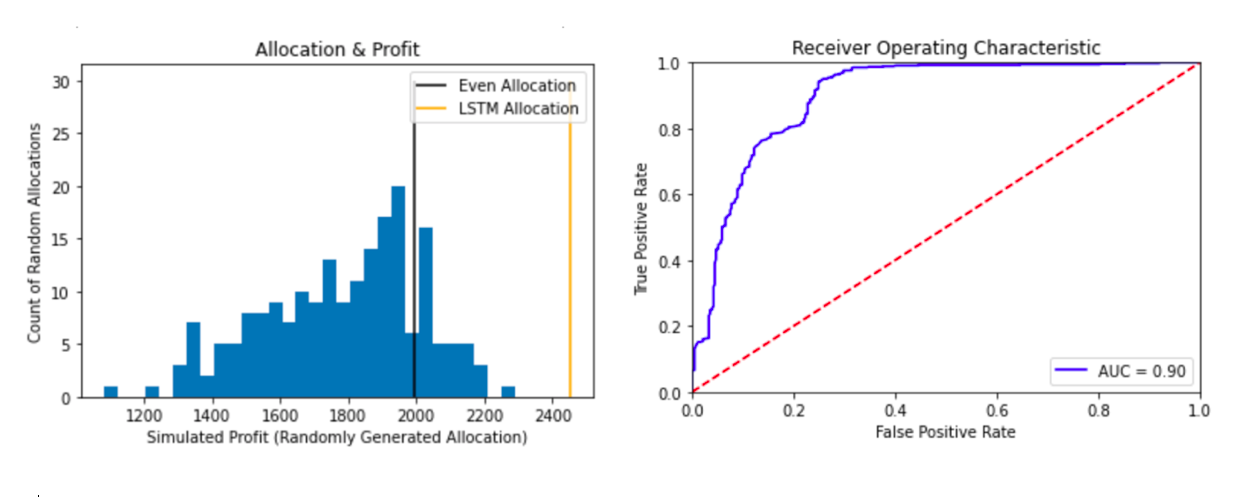
The output from this step, which involves training a network whose sole purpose is to provide recommended allocation weights, is the input into our larger simulation architecture which is agnostic to where the allocation weights themselves came from.
Product Pipeline
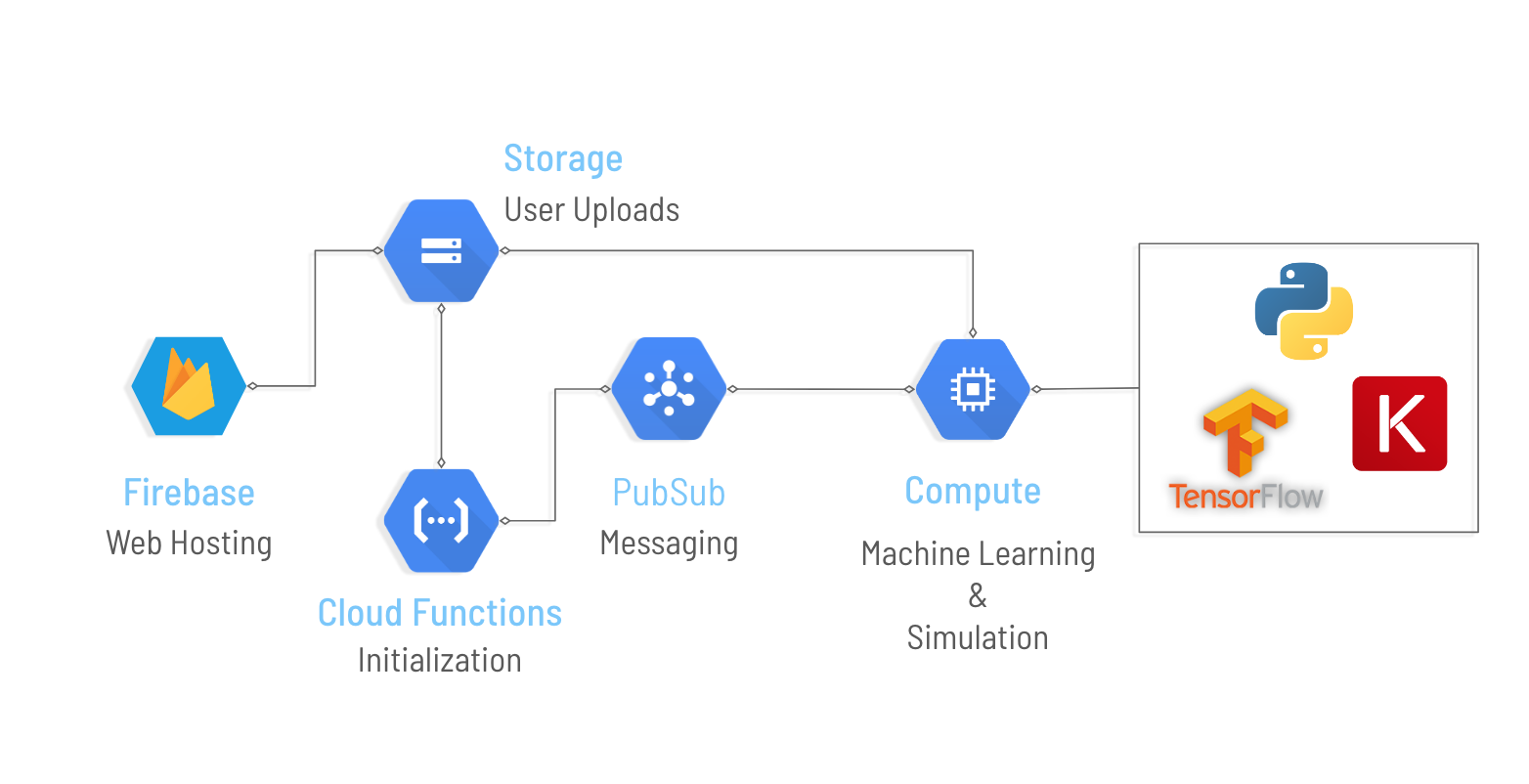
Becasu was built using the Google Cloud suite of products. Users upload their data through our website, which is hosted through Google Firebase.Their data is stored on a secure Google Storage bucket where a combination of Cloud Functions and Messaging transform their upload and interact with our backend compute engine for processing. Our ML and Simulation pipeline is implemented in python using Keras with Tensorflow.
reference
- Katsov, Ilya. “Cross-Channel Marketing Spend Optimization Using Deep Learning.” Grid Dynamics Blog, 26 June 2019, blog.griddynamics.com/cross-channel-marketing-spend-optimization-deep-learning.
- Shao, X. and Li, L. (2011). Data-driven multi-touch attribution models. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 258–264.ACM.
- S. K. Arava, C. Dong, Z. Yan, A. Pani, et al. Deep neural net with attention for multi-channel multi-touch attribution. arXiv preprint arXiv:1809.02230, 2018.